

科研进展 | 我院智能媒体与视觉计算实验室2篇论文被国际顶级期刊TPAMI接收发表
2025-09-12
近日,宁波数字孪生(东方理工)研究院智能媒体与视觉计算实验室2篇论文被国际顶级期刊TPAMI接收。
TPAMI(IEEE Transactions on Pattern Analysis and Machine Intelligence)是人工智能领域最具权威性的顶级期刊之一,由IEEE主办,自1978年创刊以来,一直引领模式分析、机器学习和计算机视觉等前沿研究。它发表了众多奠基性论文,推动了AI技术的全球创新与应用。根据最新数据,TPAMI的影响因子(IF)高达18.6,稳居计算机科学-人工智能分区Q1榜首,期刊的CiteScore约为35,h-index达350以上,投稿接受率仅约10%,彰显其卓越的学术影响力。
NaviNeRF++: Towards Interpretable 3D Reconstruction via Unsupervised Disentangled Representation Learning
作者:Baao Xie, Zequn Zhang, Huanting Guo, Qiuyu Chen, Hu Zhu, Bohan Li, Wenjun Zeng, Xin Jin
论文地址:https://ieeexplore.ieee.org/abstract/document/11144453/
论文介绍:近年来,人工智能的迅猛发展推动了传统三维重建技术的重大升级,并为该领域的创新提供了新的可能性。与传统的显式建模形式(如点云、网格和体素)相比,以神经辐射场(NeRF)为代表的三维隐式重建方法在重建质量、内存消耗和对人工标注的依赖性方面具有显著优势。然而,由于真实三维环境的复杂性和人工智能的局限性,现有基于NeRF的三维重建模型依然面临着可解释性和可控性方面的问题。具体而言,现有以深度网络为核心的“黑箱”隐式重建技术是一种捷径学习策略,这种方法没有模拟人类通过解耦语义表征获取三维世界物理规律的过程,而是直接基于大规模数据训练网络以拟合输入与输出之间的映射关系。这类黑箱策略导致了现有技术的不可解释性和不易控制性问题,制约其在复杂任务和敏感领域的应用。
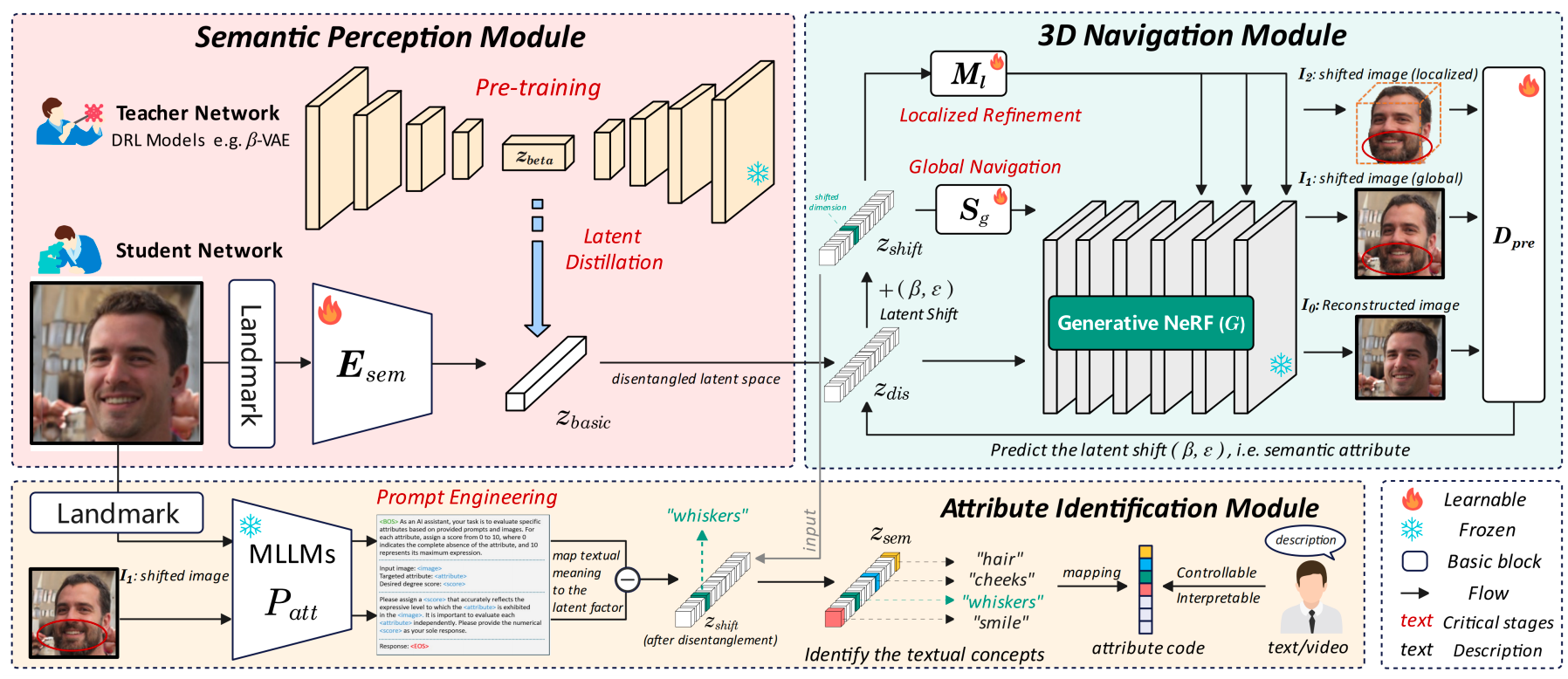
图一: NaviNeRF++的整体框架图
针对上述问题,我们提出了一个可解释的三维重建模型NaviNeRF++。该模型包含了:1)基于隐式蒸馏的语义感知模块、2)基于神经辐射场的三维重建模块、以及3)基于多模态大模型的属性定义模块。具体而言,模型在获取输入图像后,以预训练的解耦表征学习网络作为教师网络,以语义编码器作为学生网络,以所述输入图像作为所述语义编码器的输入,通过隐式蒸馏技术,得到可解释的隐变量;接着,模型对所述可解释的隐变量施加随机采样的偏置,分别通过可训练的仿射变换、映射变换采样W+空间,利用预训练的生成式神经辐射场分别得到三维重建后的外置粗粒度解耦图像、内置细粒度解耦图像,以最小化包括重建损失、协同损失和一致性损失的损失函数为目标,对偏置进行训练,得到解耦表征向量;最后,模型利用多模态大模型识别所述输入图像以及内置细粒度解耦图像中的最大区分度的属性,建立属性与解耦表征向量的关联,最终实现语义化的三维重建和细粒度的三维解耦。

图二:NaviNeRF++重建的三维场景,具备细粒度属性的可解释性和可控制性。
OccScene: Semantic Occupancy-based Cross-task Mutual Learning for 3D Scene Generation
作者:Bohan Li, Xin Jin, Jianan Wang, Yukai Shi, Yasheng Sun, Xiaofeng Wang, Zhuang Ma, Baao Xie, Chao Ma, Xiaokang Yang, Wenjun Zeng
论文地址:https://ieeexplore.ieee.org/document/11139101
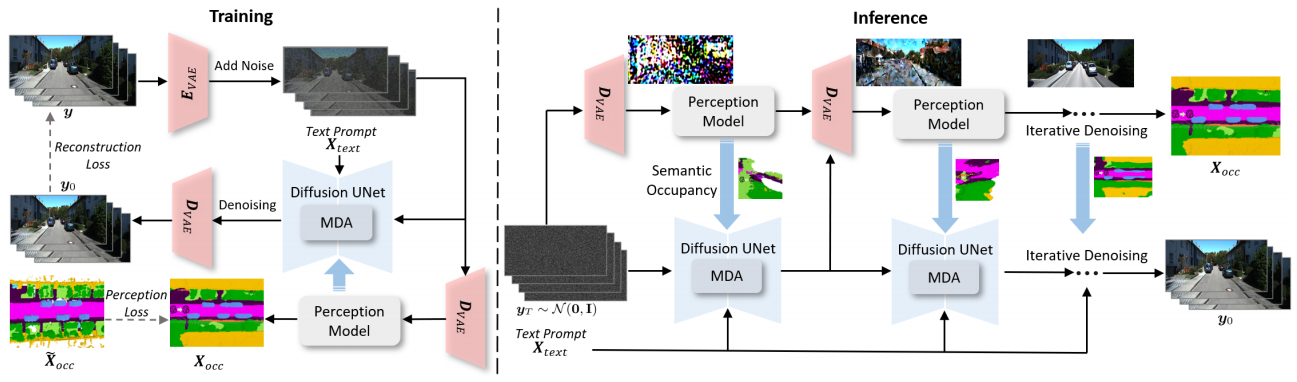
图三: OccScene的整体框架图
论文介绍:我们提出的OccScene是一个创新的统一框架,旨在解决当前3D场景生成与感知任务相互割裂的核心痛点。传统方法通常将生成模型简单地用作下游感知任务的数据增强器,这种单向流程存在灵活性差、约束力弱、目标不明确等固有缺陷。OccScene提出了一个生成与感知协同进化的统一范式,实现了仅依赖文本输入即可同步生成高质量3D场景图像及其细粒度语义占据网格,并在两个任务上均实现了显著的性能提升。核心创新与贡献如下:
1.统一的联合学习范式 (Unified Joint Learning Paradigm): 我们首次将3D语义占据预测与文本驱动的扩散生成模型置于一个框架中进行端到端联合训练。该框架不再依赖昂贵的真实标注数据(如3D包围盒、高精地图)作为生成条件,而是通过感知模型提供的语义占据先验来引导生成过程,同时利用生成的高质量、多样化数据反哺感知模型,形成正向循环的互学习机制。
2.基于Mamba的双重对齐模块 (MDA):为了将语义占据这一强大的几何与语义先验有效注入到扩散模型的潜在空间中,我们设计了MDA模块,通过跨视角相机编码将相机轨迹信息融入占据特征,确保多视角生成的一致性;并通过基于状态空间模型(SSM)的序列特征编码,以线性复杂度高效地对齐语义占据(深度维度)与扩散潜在特征(时间维度),实现了上下文信息的精准融合。
3.场景感知的迭代生成与增强:框架内生的感知模型能够对生成过程中的噪声图像进行解读,提供逐步清晰的语义占据图,从而动态地、精细地约束生成过程,确保输出内容的几何合理性与语义真实性。
基于以上架构和模块,模型在室内(厨房、卧室)和室外(驾驶场景)多种环境下实现了精确的、泛化的3D场景感知和生成,并能够进行多视角一致且时序连贯的视频生成。

图四:OccScene生成效果展示
来源:智能媒体与视觉计算实验室
编辑:综合管理部