

我院智能媒体与视觉计算实验室多项成果被人工智能和机器学习领域顶级会议NeurIPS 2024接收
2024-09-30
近期,中国计算机学会(CCF)推荐的A类国际学术会议NeurIPS 2024论文接收结果公布,宁波数字孪生(东方理工)研究院智能媒体与视觉计算实验室在本次会议中投稿的3篇论文全部入选(包含一篇Spotlight)。神经信息处理系统大会(Neural Information Processing Systems,简称NeurlPS)与国际机器学习大会(ICML)、国际学习表征会议(ICLR)并称“机器学习三大顶会”,在人工智能及计算机理论领域享有极高的学术声誉。 据悉,第38届NeurIPS会议,将于2024年12月9日-15日在加拿大温哥华会议中心召开。实验室本次发表的三篇工作,研究方向涵盖解耦表征学习、多模态大模型、强化学习等,成果简介详见下文。
招生招聘
实验室长期招聘具有人工智能、计算机视觉、智能媒体处理等相关专业背景的优秀博士生、博士后、研究序列人员(RAP)、工程师序列人员、实习生,欢迎加入。
联系人:金鑫(jinxin@eitech.edu.cn)
- 1 -
Graph-based Unsupervised Disentangled Representation Learning via Multimodal Large Language Models
作者:Baao Xie, Qiuyu Chen, Yunnan Wang, Zequn Zhang, Xin Jin, Wenjun Zeng
录用:Conference on Neural Information Processing Systems (NeurIPS 2024)
论文地址:https://arxiv.org/pdf/2407.18999
论文简介:解耦表征学习(Disentangled Representation Learning, DRL)通过探索大数据内部蕴含的物理机制和逻辑关系复杂性, 从数据生成的角度解耦数据内部多层次、多尺度的潜在生成因子, 促使深度网络模型学会像人类一样对数据进行自主智能感知, 逐渐成为新一代基于复杂性的可解释深度学习领域的重要研究方向。然而,现有的DRL方法往往假设语义表征完全独立,但这在真实世界中并不成立,例如属性“年龄”和“发际线”并不相互独立而是呈现负相关性、属性“窗户”和“光照”则呈现正相关性,这种表征属性间的联系不应该被忽视。为了解决这一问题,我们引入了一种基于大模型和双向加权图的框架,用于学习复杂数据中的解耦表征及其相互关系。具体而言,我们提出了一个基于β-VAE的模块来提取表征属性,作为图结构的初始节点,并利用多模态大语言模型来发掘潜在的内在联系,从而更新图结构的边权重。通过整合这些模块,我们的模型成功实现了细粒度和无监督的表征解耦。同时由于我们的模型建模了属性之间的联系,使其能够泛化到更加真实和复杂的场景中。
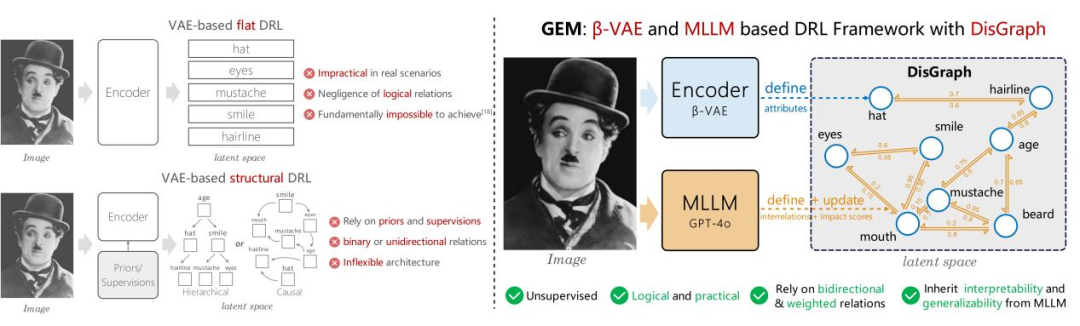
图一:GEM与传统DRL方法的区别
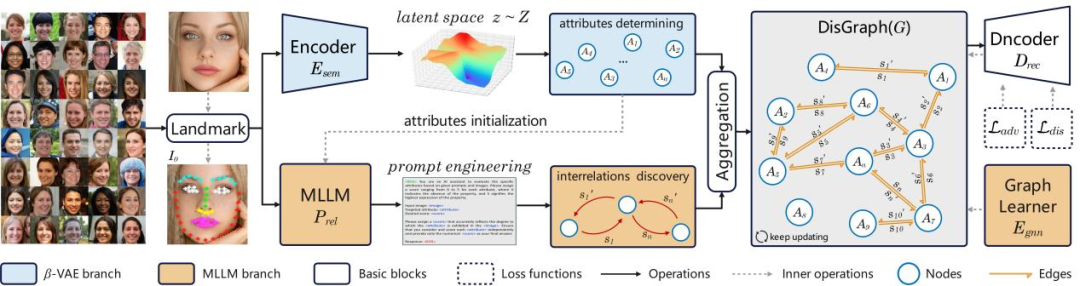
图二:GEM的基本结构图
- 2 -
Scene Graph Disentanglement and Composition for Generalizable Complex Image Generation
作者:Yunnan Wang, Ziqiang Li, Zequn Zhang, Wenyao Zhang, Baao Xie, Xihui Liu, Wenjun Zeng, Xin Jin
录用:Conference on Neural Information Processing Systems (NeurIPS 2024, Spotlight)
论文简介:近年来,随着扩散模型的发展,基于自然语言或者布局为条件的图像生成方法在质量方面已经取得了巨大的成功。然而,由于对多个对象及其关系的建模不足,这些方法难以合理地实现复杂场景的生成。为了解决这个问题,我们提出了DisCo,该方案利用场景图作为一个强大的结构化表示来生成复杂场景的图像。与以往基于场景图的图像生成方法不同,我们以一种可泛化的方式利用了变分自编码器和扩散模型的生成能力,从场景图中组合了解耦的视觉线索。具体来说,我们首先提出了一种语义-布局联合建模的变分自动编码器(Semantic-Layout Variational AutoEncoder, SL-VAE),从输入场景图中同时派生出布局和语义,从而在一对多映射中实现更多样化和合理的生成。然后,我们设计了一个与扩散模型集成的可组合的遮罩注意机制(Compositional Masked Attention, CMA),将布局,语义与细粒度属性作为生成指导。为了进一步实现输入场景图条件修改的同时保持生成视觉内容的一致性,我们引入了多层采样器(Multi-Layered Sampler, MLS)来实现“孤立”的图像编辑效果。大量的实验表明,我们的方法在生成合理性和可控性方面优于最近基于文本、布局或场景图的其他生成方案。
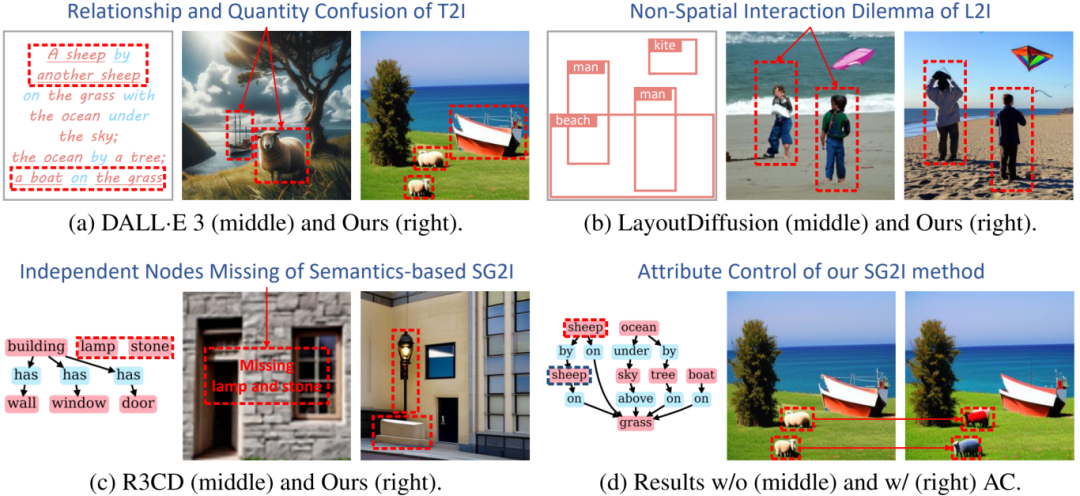
图一:DisCo在生成复杂场景图像方面的优势
- 3 -
Making Offline RL Online: Collaborative World Models for Offline Visual Reinforcement Learning
作者:Qi Wang, Junming Yang, Yunbo Wang, Xin Jin, Wenjun Zeng, Xiaokang Yang
录用:Conference on Neural Information Processing Systems (NeurIPS 2024)
论文地址:https://arxiv.org/pdf/2305.15260
论文简介:使用视觉输入来训练离线强化学习模型面临两个主要挑战,即表征学习中的过拟合问题以及对未来期望奖励的高估偏差。最近的研究试图通过鼓励保守行为来缓解高估偏差。相比之下,本工作旨在为价值估计建立更灵活的约束,而不妨碍对潜在优势的探索。核心思路是利用现成的强化学习模拟器,将其作为离线策略的“测试平台”,这些模拟器可以轻松地以在线方式进行交互。为了实现有效的在线到离线的知识迁移,我们提出了 CoWorld,这是一种基于模型的强化学习方法,用于减轻状态空间和奖励空间的跨域差异。实验结果表明,CoWorld 的表现相比现有强化学习方法有较大的优势。
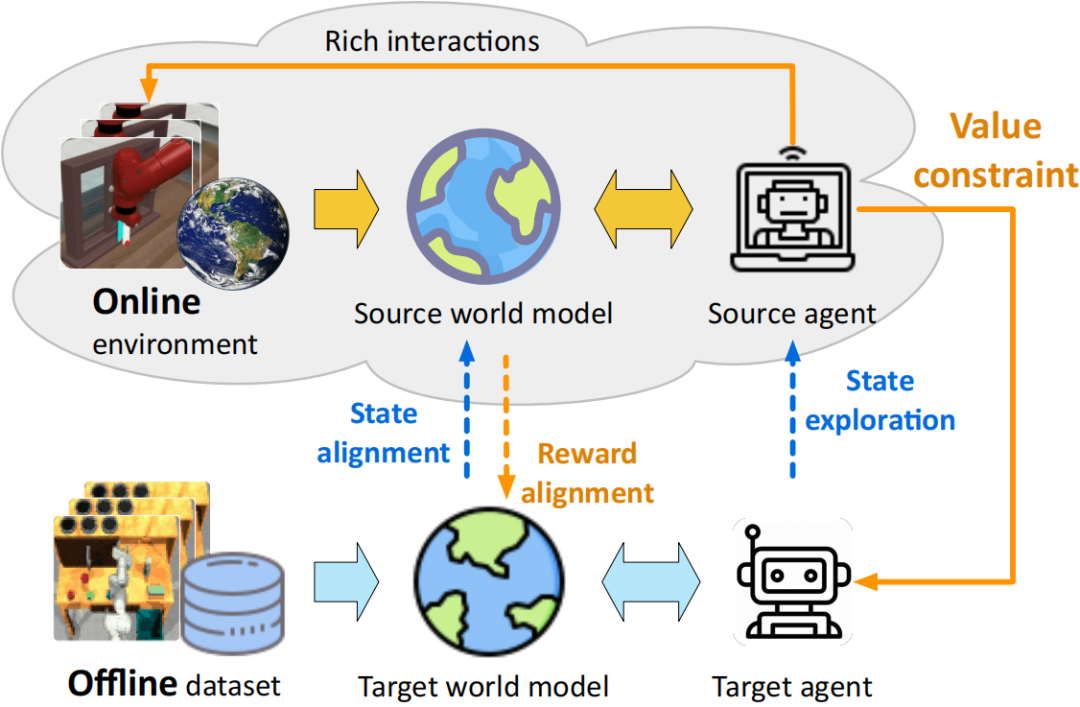
图一:CoWord 框架图
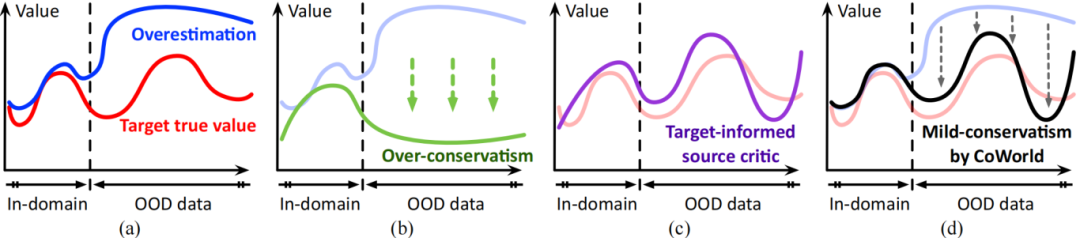
图二:离线强化学习方法价值估计对比
来源:智能媒体与视觉计算实验室
编辑:综合管理部